Architectural Leverage in the Age of Agentic Development
AI drastically accelerates code drafting, but it makes architectural intent exponentially expensive. Without upfront discipline, engineering quickly deteriorates into reactive "vibe coding." Discover how to invert the workflow and reclaim control through Spec-Driven Development.

There are two types of people in AI development right now: those who vibe code, and those who build working software.
We all know the vibe coders. In fact, if we’re being honest, most of us have been one at some point. It starts innocently. You type a three-sentence prompt into an AI assistant, and boom - two hundred lines of syntactically correct code materialize in seconds. You didn't write it, you barely understand it, but it looks beautiful. You copy, you paste, you run the server. It crashes.
You feed the error back to the AI. “My bad” the AI says, oozing unearned confidence. It spits out another two hundred lines. You paste them. It works! You don't know why, the AI doesn't really know why, but the vibes? The vibes are immaculate.
Until three days later, when your hyper-accelerated codebase has suffered a complete structural meltdown.
The marginal cost of software generation has collapsed to near zero. But this hyper-acceleration has exposed a dangerous reality: when code becomes a cheap commodity, clarity of architectural intent becomes exponentially expensive. This instructional hacking causes rapid semantic drift - the gradual, silent loss of structural meaning, intent, and architectural trust as an agent refactors your codebase at 500 tokens per second.
Escaping the Vibe Loop
To survive the era of generative AI, we have to put away the vibes and invert the workflow.
I learned this the hard way. For a long time, my experience with offloading larger pieces of work to autonomous AI agents was... less than magical. If I'm being honest, I was basically vibe coding my way through it. I found myself forced to babysit the AI, directing it at every single micro-step, fixing a hallucinated package import here, patching a weird variable name there.
The worst part? Once the code was finally written and "working," I looked at the repository and realized I had completely lost my grip on the system. The codebase had expanded into a massive, machine-generated black box. I didn't fully understand what had just happened, and modifying it further felt like defusing a bomb.
I was generally unhappy with the fact, that iteration with the AI model felt cumbersome.
Then, everything changed. I was scrolling through Martin Fowler’s blog and stumbled across the concept of Spec-Driven Development (SDD) [1].
It clicked immediately.
We needed to do what we always did: Describe what, why and then how.
To understand why this shift is so powerful, we have to look at software design through a model I call The Cone of Human Influence.
The Cone of Human Influence : Detail vs. Leverage
In traditional project management, McConnell’s Cone of Uncertainty maps estimation variance. In the AI era, we must map a more critical relationship: The Cone of Human Influence. This framework visualizes the dualism between the volume of details a human mind must process and the strategic leverage human decisions exert across a project's lifecycle.
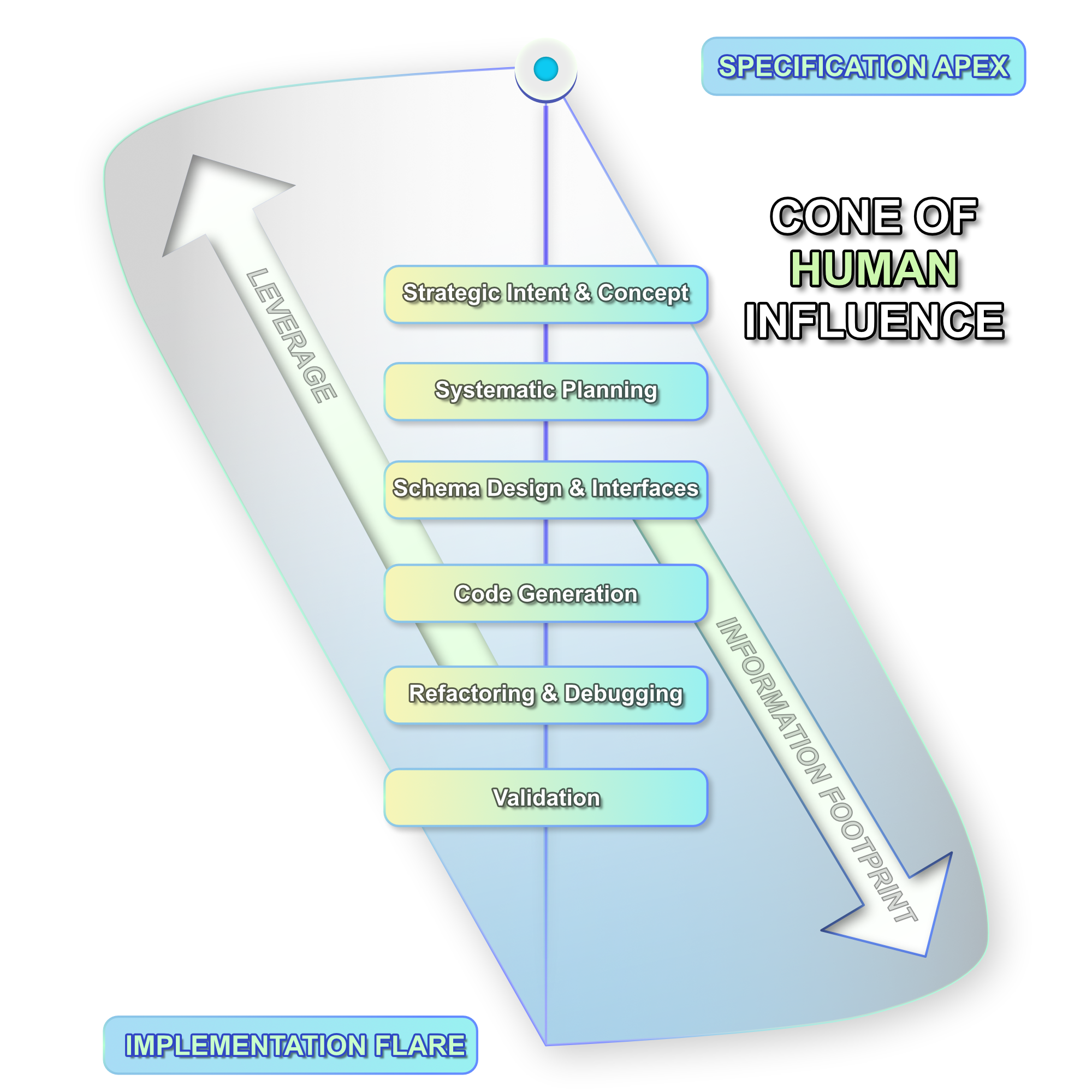
1. The Apex (High Leverage, Low Detail)
At the top of the cone, you are dealing with high-level intent, API schemas, and validation boundaries. The information footprint is microscopic. Because the volume of detail is low, you can easily hold the entire architecture in your working memory. A one degree shift here cleanly redirects the downstream trajectory of the system at zero cost or can bring upon catastrophic results.
2. The Flare (Low Leverage, High Detail)
As the project compiles down into concrete code, details explode exponentially into thousands of lines of nested syntax, package dependencies, and infinite runtime states. If you bypass the apex and vibe-code directly at the base, you are instantly flooded with machine-generated details. You are no longer an architect; you are a reactive firefighter writing fragile, local workarounds to patch over a system you no longer fully control.
The Golden Rule of AI Architecture: The machine compiles the details; the human must master the apex of the cone.
The Cost of Bad Design
Historically, software economics (via Barry Boehm) [2] demonstrated that a requirements defect caught post-delivery can be up to 100x more expensive to fix than one caught during the design phase. In AI-native workflows, this exponential cost curve is steepened, not flattened.
If you give an agent an incomplete, "vibed" requirement like "Build an order placement API," it will happily produce the output. In some cases, it may even ask you a clarifying question or two, giving you the comforting illusion that you are in total control.
But beneath the surface, the agent starts making unguided structural choices:
- It selects a language, library, or framework tier you didn't expect or want.
- It fakes critical upstream API calls.
- It bypasses security configurations to make things "work."
- It hardcodes test expectations to artificially green a pipeline.
Remediating these systemic gaps after the AI has generated a massive web of tightly coupled code requires extensive, token-wasting refactoring. A 10-minute review of a specification at the apex of the cone saves hours of downstream prompt-tuning and manual debugging.
Spec-Driven Development: Reclaiming the Apex
If letting AI write code without a plan is a fast track to architectural bankruptcy, how do we fix it?
We change the rules of engagement.
Since GitHub released Spec Kit we have seen an entire ecosystem building around and upon it. It is an open-source CLI designed to translate human-readable, machine-verifiable specifications into deterministic test suites and boilerplate. It’s specifically built to let engineers take back control of the architecture while still offloading the heavy lifting of raw implementation to AI agents. Alongside Spec Kit, a whole tooling ecosystem has quickly emerged.
But regardless of the specific tools and frameworks you choose, the core philosophy of Spec-Driven Development (SDD) remains exactly the same:
A human explicitly specifies the scope of what, why, and how a project, feature, or smaller component will be implemented. The AI’s job isn’t to guess your intent; its job is to help you refine, validate, and compile that intent into working software.
Instead of traditional workflows where code is the primary source of truth and documentation is an afterthought, SDD introduces a strict, automated hierarchy:
- The Spec is the Master: The human-authored specification is the absolute, authoritative source of truth.
- The Code is a Compiled Artifact: Machine-generated code is treated as a secondary, compiled, and mathematically verifiable byproduct of your specification.
By shifting your energy from writing line-by-line syntax to designing bulletproof specifications, you stop playing whack-a-mole with local bug fixes. If a feature needs to change, you don't rewrite the code—you rewrite the spec, and let the agent re-compile the reality.
But SDD isn't one-size-fits-all. Depending on your team's needs and how much control you want to retain, you will find yourself operating across a sliding spectrum of specification rigor. To operationalize that rigor and take back control, you can implement the following processes and guidelines with your team.
Table 1: Specification Rigor Spectrum
Technical Protocols for Reclaiming the Apex
Coding at 500 tokens per second means you can no longer manage systems through manual code reviews and good intentions alone. To scale your architecture without losing your sanity, your team needs an unyielding engineering pipeline.
Implementing Spec-Driven Development isn't a matter of corporate policy; it's about introducing strict, automated physical boundaries to protect the codebase from machine-generated chaos. If you are ready to stop vibe coding and establish true architectural governance, the following are some tactical protocols you can build into your workflow:
Enforce the "No-Code-Without-Spec" Boundary
Before assigning any task to an AI agent, a human developer must author a structured specification detailing the happy path, error handling, validation schemas, and telemetry requirements. Do the heavy cognitive lifting while the information footprint is small.
Standardize Persistent Context Guidelines
Establish versioned, audited context, instructions, or system prompt files to restrict agent degrees of freedom. Ensure your architectural invariants are codified so the AI cannot deviate from team standards.
Move to Spec-Anchored, Contract-First CI/CD
Assert system behavior at the API contract level rather than relying on brittle UI automation. By flipping the testing "ice cream cone" anti-pattern into a true spec-anchored pyramid, you catch architectural drift the exact second code is generated. This speeds up the agentic loop, shortens feedback cycles, and ultimately produces significantly better results.
Module-Boundaries Matter More Than Ever
When code generation takes only minutes, a codebase can double in size over a single weekend. If your internal boundaries are fuzzy, an autonomous AI agent will treat the entire system as an unconstrained playground, aggressively introducing hidden couplings and circular imports just to make an immediate feature work. Inside a module, let the AI refactor and optimize as fast as it wants - but the second it needs to communicate with another domain, it must be forced to use an explicit, unyielding public API or data contract. Strong boundaries isolate the machine-generated chaos; if an agent introduces semantic drift, the damage is contained to a single room instead of burning down the whole house.
Provide the Means To Close The Loop
An execution pipeline is only as good as its feedback mechanism. If the AI agent generates code that breaks an invariant, the pipeline must automatically feed the precise failure metrics, such as compiler errors, linting violations, or broken contract boundaries, directly back into the agent's context window. Closing this loop turns a passive generator into a self-correcting engine, allowing the AI to autonomously resolve implementation bugs without sucking human developers back into the line-by-line debugging fire.
Finalize with Documentation for Humans
When an agent successfully generates or refactors code, it must be mandated to output clean, high-level documentation of how the specification was realized. This isn't about generating endless, useless code documentation lines over every method. It means generating structural maps, updated architecture decision records (ADRs), and boundary guides. Humans should never have to reverse-engineer machine-generated code just to understand how a component works; the AI must document its execution for human review.
Automate Architecture Guardrails
Do not rely on humans to catch structural violations during code reviews. Implement automated static analysis tools, custom linters, and architectural enforcement tools (like ArchUnit or native AST parsers) directly in your pull request pipeline. If an agent attempts to bypass a boundary - such as importing a database model directly into the presentation layer - the guardrail must instantly reject the commit. By gating the codebase automatically, you ensure that even the fastest AI agent cannot break your system's macro-architecture.
Use Concepts of Evolutionary Architecture
In an AI-native ecosystem, code becomes fluid, but the system's core capabilities must remain resilient. Design your software using evolutionary architecture paradigms, utilizing modular monoliths or loosely coupled microservices bounded by clean interfaces. By protecting your system with automated "fitness functions"—such as performance budgets, security scanning, and dependency analysis—you can allow AI agents to aggressively rewrite, optimize, and replace entire implementation blocks over time without risking the systemic collapse of the platform.
There is No Perfect Spec
As engineers, we love a deterministic silver bullet. It is easy to look at Spec-Driven Development and fall into the trap of believing that if we just write the perfect specification, the AI will flawlessly compile our intent 100% of the time and produce the same result every time.
That will not happen.
AI agents are fundamentally probabilistic systems built on top of Large Language Models. They do not interpret a specification the way a compiler interprets source code; they predict the next tokens based on statistical patterns. This means that even with a pristine, air-tight specification:
- The AI will still misinterpret context. It can subtly misread a business boundary or misalign a performance trade-off based on weights hidden deep inside its neural network.
- Edge cases defy upfront definition. Software design is an emergent process. You rarely know every constraint until you actually touch the boundaries of runtime execution.
- The "Garbage In, Garbage Out" rule scales up. If your spec has an implicit logical flaw, the AI may build and amplify the mistake. Worse yet, there is a subtle paradox here: If you use an AI assistant to help you write, refine, or validate your specification at the apex, you haven't actually eliminated unguided statistical choices - you’ve just outsourced them upstream. If the model's underlying weights harbor hidden biases or flawed assumptions, those flaws will be baked directly into your "authoritative" source of truth.
SDD is not about eliminating human intervention; it is about changing where humans intervene.
We are moving human engineering from line-by-line manual syntax generation to high-level systemic oversight. Even in a mature Spec-as-Source ecosystem, the human developer must remain an active pilot for reviewing generated logic, auditing edge cases, and adjusting the spec when the AI encounters a dead end. If you completely hand the keys to the agent under the assumption that your spec is "perfect," you shift vibe coding to vibe specification.
Conclusion
Human influence in software engineering is fundamentally scale-dependent. As systems scale down from abstract specifications to massive, compiled codebases, our cognitive capacity is overwhelmed by detail, and our strategic leverage decays to zero.
Spec-Driven Development and Context Engineering aren't just trendy paradigms - they are the operational mechanisms required to anchor human control where it matters most.
The future belongs to the architects who spend less time writing line-by-line syntax and more time defining, auditing, and enforcing upfront intent. Master the cone, protect your architecture, and take back control.
References
[1] Understanding Spec-Driven-Development: Kiro, spec-kit, and Tessl, https://martinfowler.com/articles/exploring-gen-ai/sdd-3-tools.html, Written by Birgitta Böckeler
[2] Software Engineering Economics, Barry W. Boehm, Prentice-Hall 1981
[3] Github Blog, Spec-driven development with AI: Get started with a new open source toolkit, https://github.blog/ai-and-ml/generative-ai/spec-driven-development-with-ai-get-started-with-a-new-open-source-toolkit/